Universe[]
The sign/glyph sequences in the language, occasionally (or more) appearing in writing or printing are the objects of study. Correctness, historical reasons of current state are not directly relevant .
Soundness and completeness[]
Model of encoding should be true to the underlying deep structure of script, and should be capable of producing all the words in the 'universe'. For soundness example, a standard user of the language does not expect 'ക' to be part of the word 'ആന'; and the encoding model should meet that standard user expectations.
Uniqueness Theorem[]
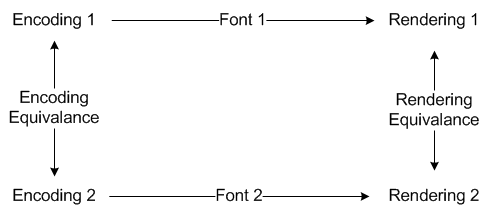
Two encoding are equivalent if they differ only joiners. Encoding of 'ശബ്ദം' and 'ശബ്ദം' are equivalent because they are be different only by a ZWNJ. Meanwhile, encoding of 'അവൻ' and 'അവന്' are not because one has chillu letter, other hasn't.
Rendering equivalence is more of a subjective thing. We know 'ശബ്ദം' and 'ശബ്ദം' are equivalent renderings. 'അവൻ' and 'അവന്' are not equivalent renderings. 'അല്പം' and 'അൽപം' are sometimes considered equivalent, sometimes not. Ambiguous pairs can not participate in this rule.
The fonts can vary from the new orthography font Nila from Bhasha Institute to old orthography fonts like Anjali or Rachana. I don't think it is realistic to consider fonts which don't have lesser number of conjuncts than Nila.
Uniqueness Rule has following 2 components:
Part 1: Encoding Equivalence implies Rendering Equivalence[]
If a word is displayed correctly in one font then that word should be rendered correctly as the same word, in all fonts.
If Encodings 1 and 2 are exactly the same and Rendering 1 and 2 are different, then there is no guarantee that the text written by one will be able to read by others.
If Encodings 1 and 2 are different by some joiners and Rendering 1 and 2 are different but valid, then there are following issues:
- search for rendering 1 will produce results with rendering 2
- search and replace would spoil the text
- Since typical language tools like spell checker or grammar checker is transparent to joiners (joiners are supposed to be font directives only), we will need to make special tools which are joiners-aware for Malayalam.
If Encodings 1 and 2 are different by some joiners and one of the Renderings 1 and 2 is valid and other is invalid, then there is following issue:
- Since typical language tools like spell checker or grammar checker is transparent to joiners (joiners are supposed to be font directives only), we will need to make special tools which are joiners-aware for Malayalam.
Part 2: Rendering Equivalence implies Encoding Equivalence[]
Two different encodings should not render same, irrespective of the font or joiners used.
Two see why this rule is required, assume there is a conjunct formation rule for a subset of Chillu-C1 + C2 permutations and as per that rule, Chillu-NNA + DDHA (ൺ + ഢ) can form the conjunct (ണ്ഢ) in an old orthography font. Of course, NNA + VIRAMA + DDHA (ണ + ചന്ദ്രക്കല + ഢ) will also form the same conjunct.
There fore, a document (eg: a wiktionary.org document) written by multiple people using various inputting tools can quite possibly have both spellings for ണ്ഢ, without reader or writer being aware of it. This can cause many problems including
- ineffective searches
- inconsistent sorted lists
- IDN security
Antoine Leca write this related text: "Right now (for fifteen years really), we have a similar problem with Latin in Europe: our accentuated letters have two spellings, one which is the legacy one (using unique code points, for example U+00EE (î) which is the one everybody uses; and the other is the genuine Unicode encoding, the one we ought to use but nobody does in reality, using the base (English) letter and then another code point for the accent, i.e. U+0069, U+0302 (î)for my example above). You cannot normally see the difference, and if you do, it is just because of an imperfect Unicode support which does not render correctly the second form (things are getting better here, but still are not perfect). But if you are searching, the different spellings MAY be viewed as different, when of course it should not. Similarly, you could be allowed to enter both forms in a database field as "unique" key, when of course it should be prevented.
As this stuff is pretty evident to anyone in Europe developing in Unicode, this problems has been identified for years; and a "fix" has been developed, that is those two sequences are considered "canonically equivalent", so a "fully conforming" Unicode process should merge the two encodings for processes like searching or inserting. Please note that the majority of the tools used nowadays which deals with Unicode contents do not do that; only the tools specially prepared does it, and this comes with a noticeable performance impact."
Extended Uniqueness Rule[]
We can consider two versions of this rule. In the lenient version of this rule, at least one of the renderings should be valid. A rendering is valid when it is present in the dictionary or it is a word combination obeying grammar rules.
In the extended version of this rule, we consider all possible words, even those outside dictionary. This could be useful because these words can come from:
- Colloquial phrases, often found in novels and stories.
- Names of places, people etc.
- Future words
A negative test tool for equivalence in plain text[]
At word level, plain text and rich text representations of a word should have same meaning. For example, if 'apple' is written in italics or bold, it has the same meaning at the word level. That gives us a test tool to see whether writing of two words differ in plain text or not. The test is, just to compare their respective meaning sets. If they are different, then they are different in plain text. Consequence is that their representation should differ by first class, non-ignorable, character code values.
On the other hand, if the meaning set of both the words are the same, then it is non-consequential. For example, between 'color' and 'colour', the meaning sets are the same. However, we know that they are different in plain text.
However, this is only a negative test tool and the inverse of this rule need not be true i.e. if the two meanings are same, it does not necessarily prove that the words are equivalent.